Andrea Zhang
我不是只想"完成任务"的人。我更关心的是如何从模糊问题开始,定义产品、拆解需求、做出东西,再通过真实反馈继续迭代。
我有内容和自媒体团队的实际经验,现在把注意力集中在 AI-native products 上——更具体地说,是 0→1 阶段的产品创造。我对万事万物充满好奇,对"从模糊想法到能跑起来的东西"这个过程有强烈兴趣,也有持续投入的意愿。
BUILD_PROTOCOL
我对很多领域都有天然好奇心:AI、产品、内容、社交、运动、文化、社科。好奇心不是停在"感兴趣",而是会驱动我主动研究、拆解问题,并把想法做成可以被验证的东西。
先把模糊想法翻译成具体产品对象:谁在用、解决什么、第一眼应该理解什么。
不从"大而全"开始,而是先跑通一个最小闭环:input → process → output → feedback。
Coding agent 帮我 inspect、implement、debug、refactor,但产品判断、隐私边界和验收标准必须由我负责。
隐私和安全不是最后补上的 disclaimer,而是产品结构的一部分。
用真实反馈和 review 决定下一步,拒绝闭门造车。
PROBLEM
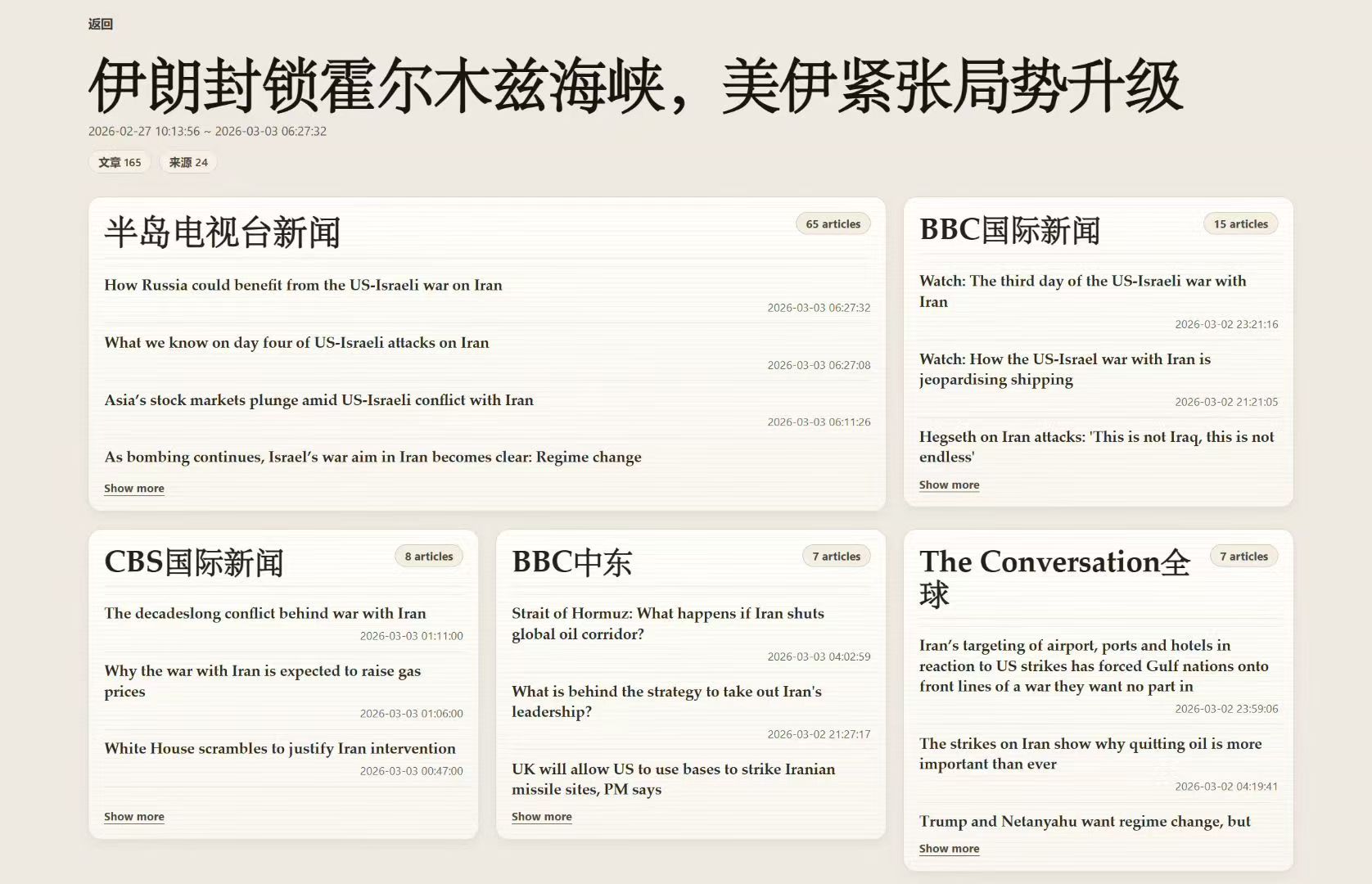
大多数新闻产品推送的是孤立的 headline 流,用户很难快速回答:这件事到底是什么?有多少来源在报道?这是一件事还是几件不同的事?
NewsToday 探索另一种阅读模式:先组织成 event,再让用户看各来源如何报道。产品的核心对象是 event,不是 article。
TARGET USER
关注全球新闻、但不想被 feed 推着走的人——学生、创始人、分析师、产品人。他们想要的是 compact briefing,而不是又一个 social timeline。
PIPELINE
MiniLM-L6-v2 → event clustering
pgvector + rules → ranking
decay + diversity → AI titles
DeepSeek → localized UI
/en · /zh
Pipeline 每 6 小时由 GitHub Actions 自动触发,live 更新。
KEY DECISIONS
MY ROLE
SCOPE BOUNDARY
不是聊天机器人 · 不是 newsroom CMS · 不是个性化推荐 · 无用户账号系统
WHAT I'D DO NEXT
- 在前端暴露 coverage matrix(现已有后端 API,前端未接入)
- 增加 event merge 的用户反馈入口
- 改进 observability:pipeline 失败和 API latency 的监控
SCREENSHOTS

👀 我就看看
这目前是一个纯个人项目,只为我自己服务,没有做多用户的数据隐私处理——所以没办法直接把真实 dashboard 开放给外部访问。
但我刚加了一个"我就看看 :)"的入口:数据是 mock 的,其他的——界面、交互、AI briefing 逻辑——和我每天在用的完全一样。进去随便逛逛。
→ dashboard-production-9aaf.up.railway.app
进去找"我就看看 :)"就行。mock 数据,无需密码。
CORE IDEA
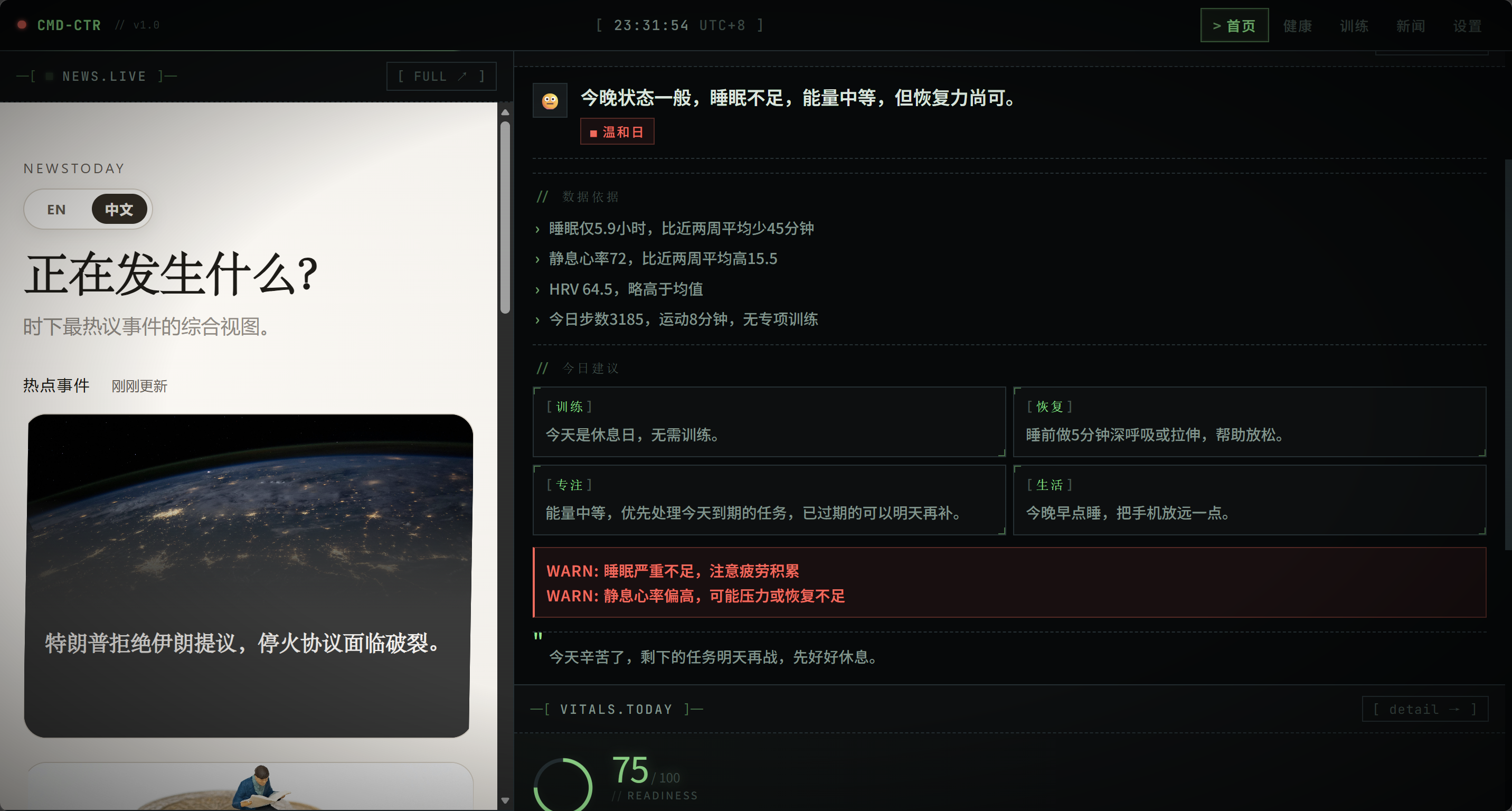
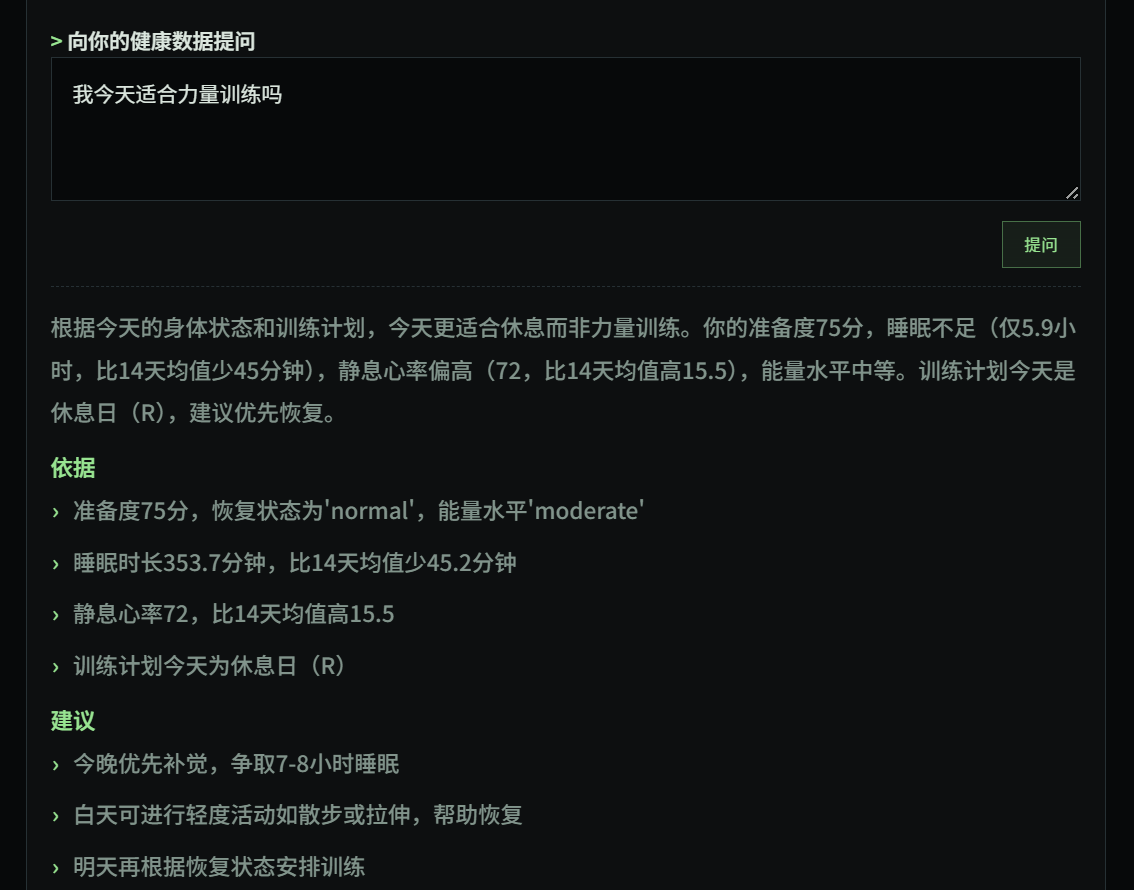
大多数 AI assistant 在没有上下文的情况下被调用——它可以聊天,但不知道你昨晚睡了多久、今天有没有 overdue 任务、本周训练负荷有多重。
Context layer first, chat second。 这个 dashboard 的核心不是"展示更多 widget",而是用真实的跨域上下文让 AI 的每日建议真正有用。
TARGET USER
同时管理知识工作、训练和个人规划的 self-directed operator——需要的是每日 command center,而不是另一个孤立的 chat 界面。
DATA FLOW
Health Auto Export → Bearer token → normalize + aggregate
readiness · HRV · sleep · steps
read-only URL, no OAuth → task cache + progress diff
ISO week storage → weekly module context
AI BRIEFING LOGIC
DeepSeek 被给予一个 compact context object,包含:readiness score、recovery status、sleep/HRV、当日任务和 overdue 情况、训练计划模块、本地时间段(morning / midday / evening / late-night)。
输出是 structured JSON,前端渲染成固定 section,不是自由文本 chat。Briefing 会被缓存,避免重复调用。
KEY DECISIONS
WHAT I'D BUILD NEXT
- 给每条 AI 建议加 source attribution:是哪个信号(sleep/tasks/training)影响了这个建议
- 把 news context 真正接入 AI briefing prompt(目前 news 只显示在 UI,不参与 briefing 生成)
- 加 LLM output 的 evaluation fixtures,避免 prompt 迭代出现 regression
SCREENSHOTS

USER INSIGHT
网球界也需要 MBTI:你的球风像哪位职业球员?上传一段你的击球视频,得到一份专属于你的风格分析报告。
PRODUCT FRAMING
这不是"AI 分析你的技术"——那个 claim 太宽也太容易 overclaim。
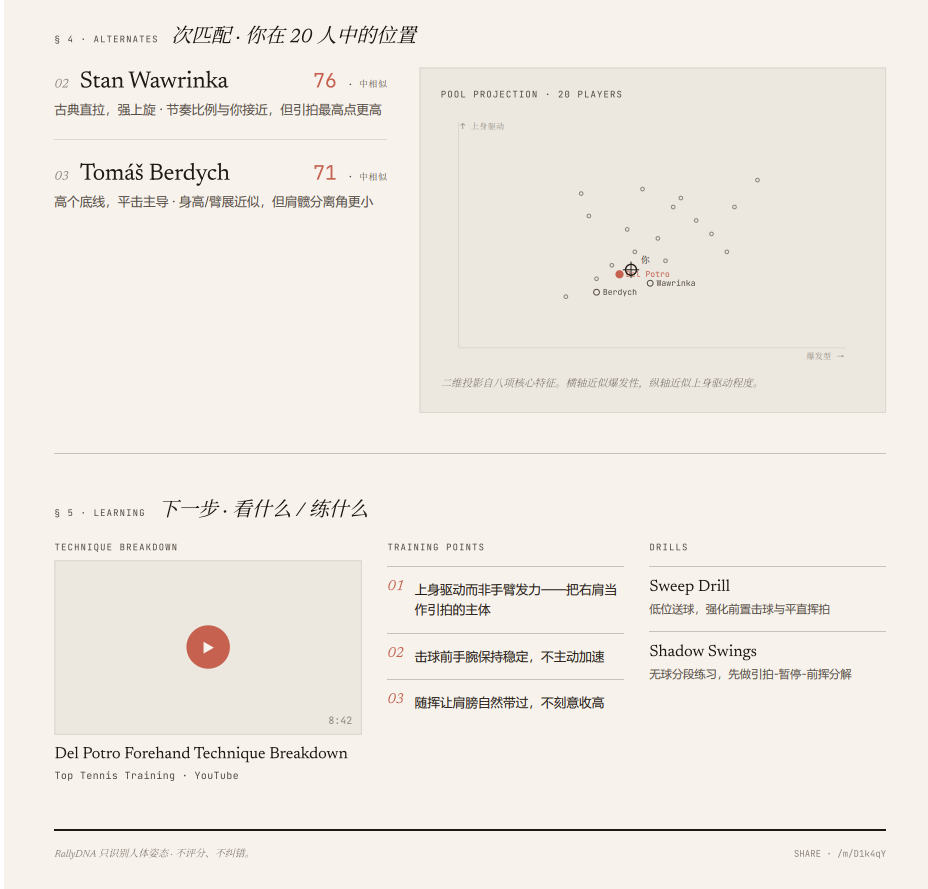
更准确的定位:RallyDNA 帮你发现你的动作模式已经最接近哪位职业球员的 forehand 风格。这个 framing 更窄、更有辨识度、也更匹配当前的技术证据。
产品类别:style-matching report,不是 coaching 工具,不是 biomechanics lab。
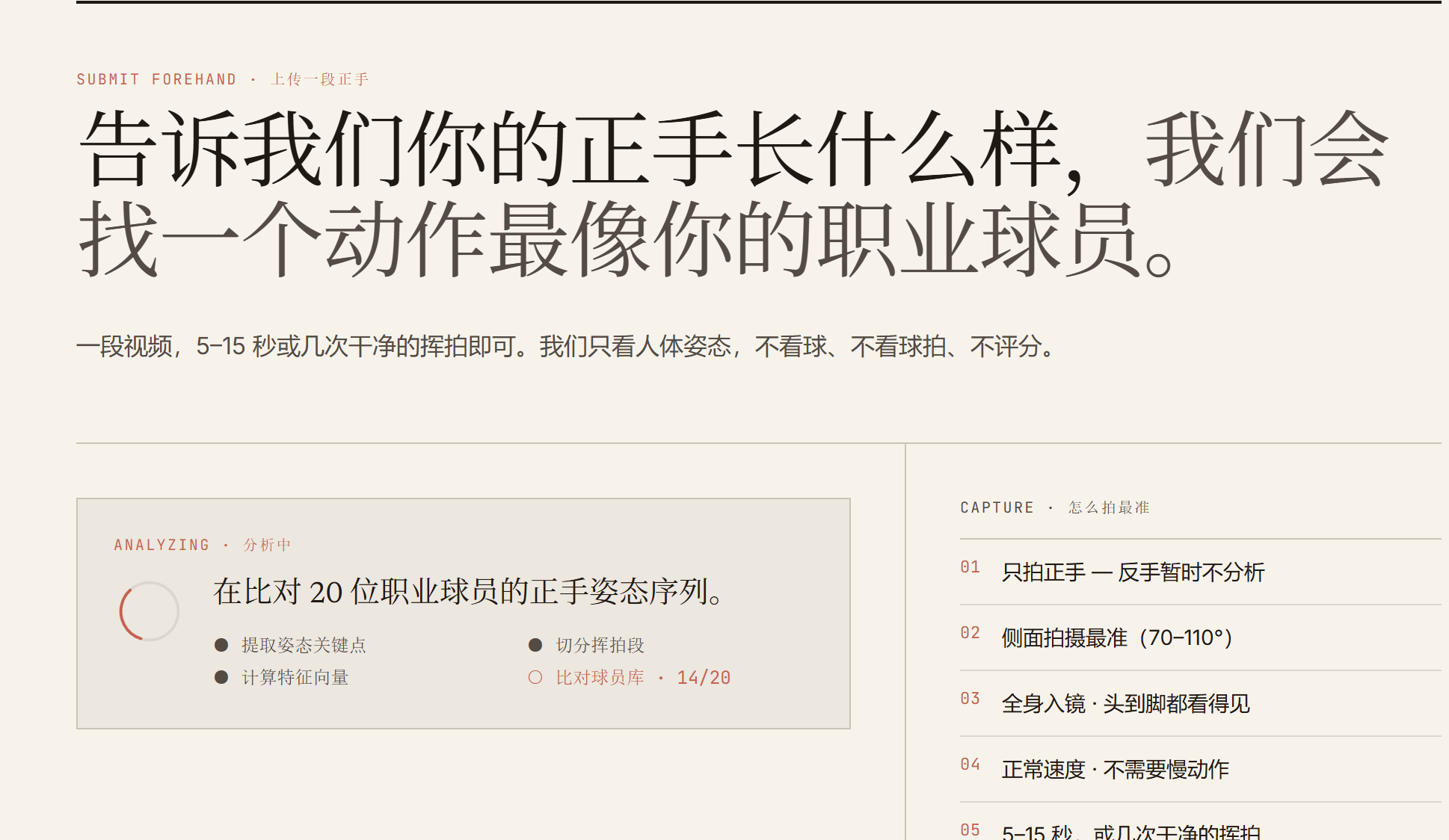
PIPELINE
pose quality check → pose landmarks
MediaPipe → swing segmentation → feature extraction → player profiles
weighted distance → style report
WHAT'S ACTUALLY MEASURED
Match score = style similarity,不是技术评分,不是 coaching grade。
REPORT DESIGN PRINCIPLES
HONEST LIMITS
- pose-only,无 ball detection,无 racket tracking,无 true contact detection
- 侧视角拍摄可靠性远高于混合角度
- 多次挥拍的视频更难 segment
- 当前 profiled player set 较小,不是 production-grade biomechanics
WHAT I LEARNED
这个项目最难的部分不是跑 pose estimation,而是决定产品应该做出什么 claim。技术限制不是边注,它们直接影响上传引导、report 的置信模型和产品 scope。把限制转成清晰的体验边界,比假装它们不存在要难得多。
SCREENSHOTS
以下为完整用户流程截图,报告页面为 demo 数据。

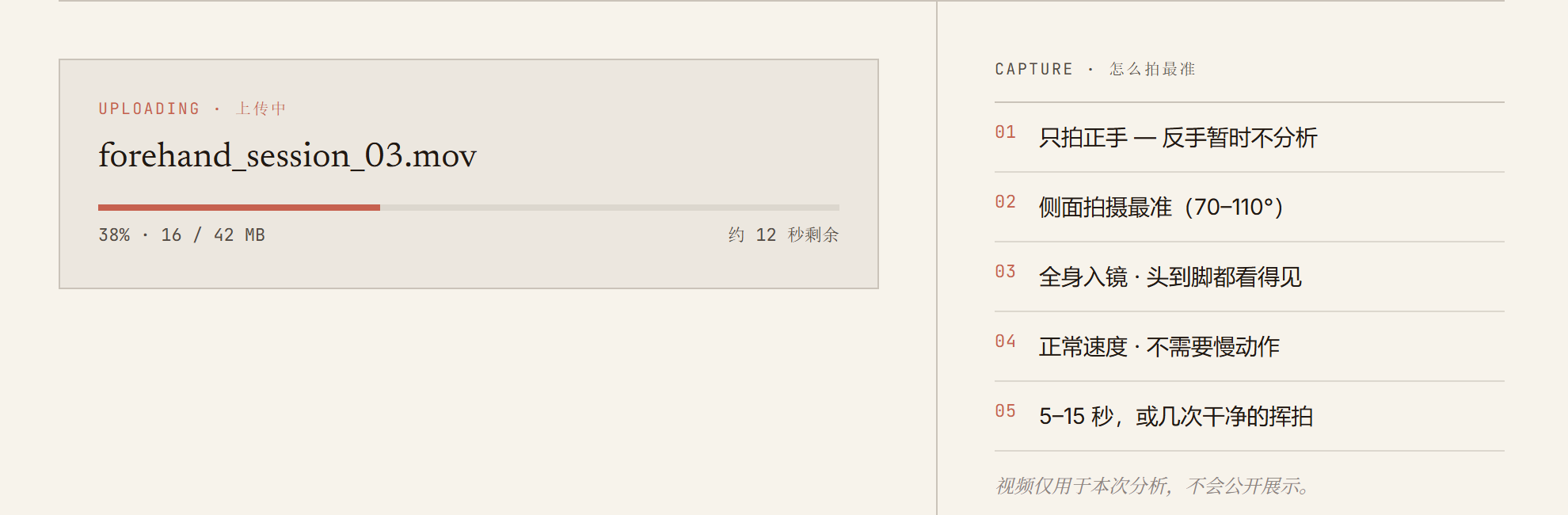
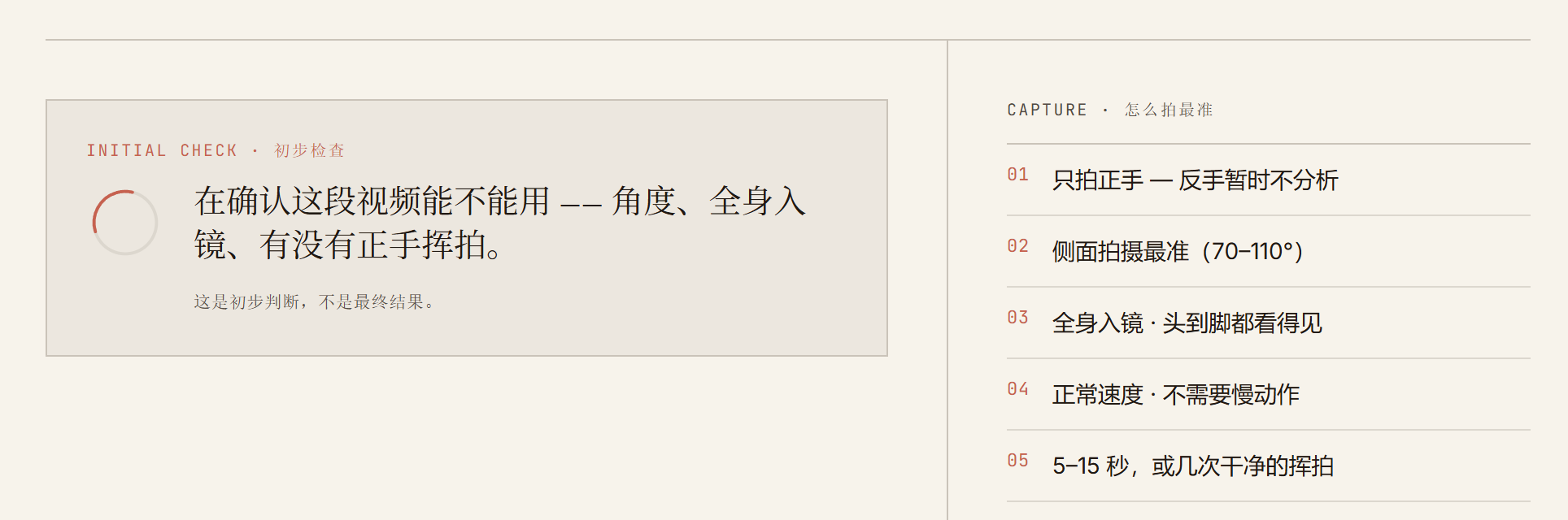
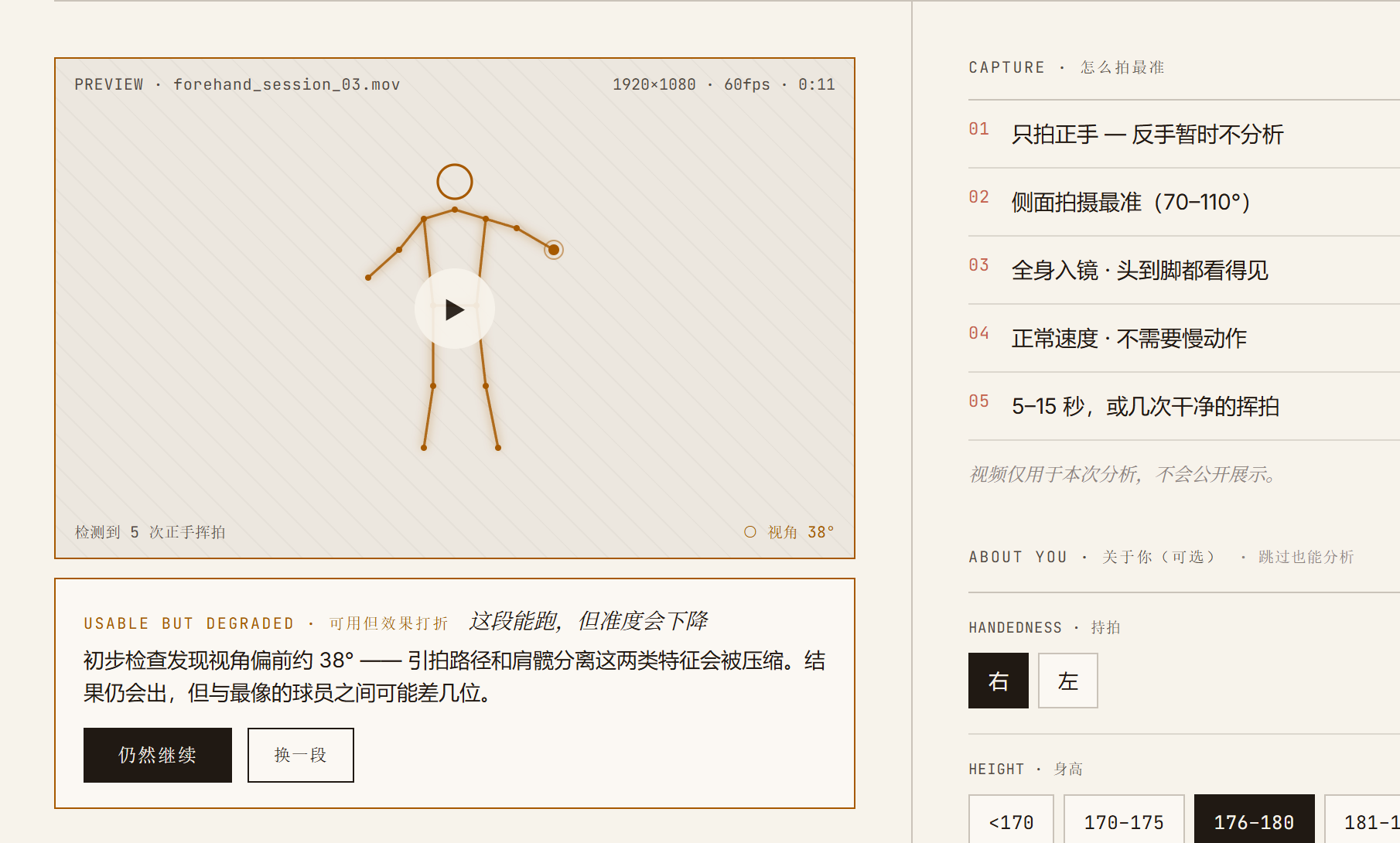
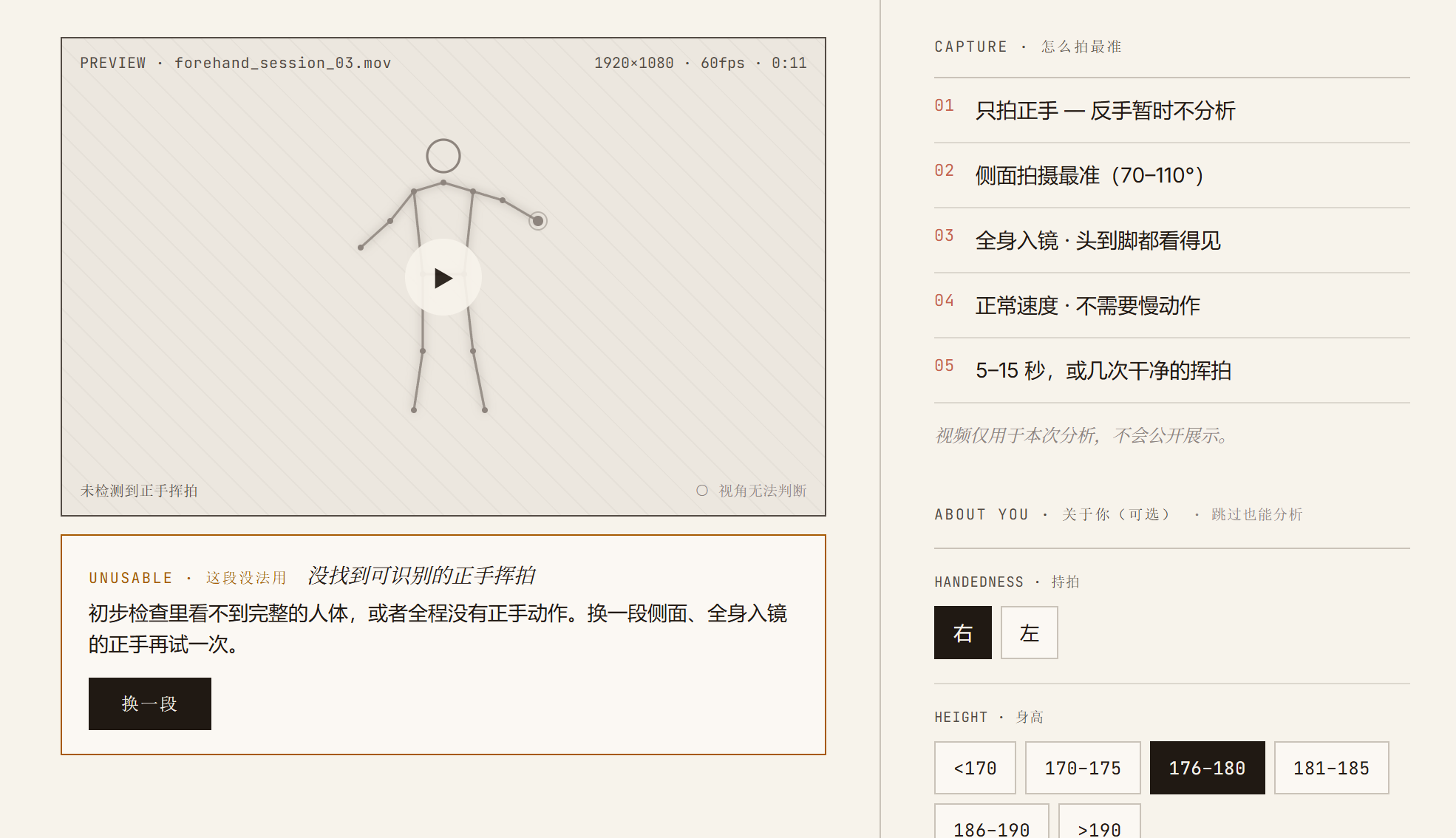


我深度使用 coding agent,但不把它当作魔法黑盒。
我的职责
- 定义问题、用户场景、需求、约束、隐私边界和验收标准
- review 输出、判断是否符合产品目标
- 测试、debug、调整 prompt
- 最终决策和方向把控
Coding Agent 的职责
- inspect files,理解现有代码结构
- implement 新功能,refactor 旧代码
- debug、write tests / docs
- 在我给定的约束内工作
WHY THIS MATTERS
用 AI coding agent 不是为了"不懂技术也能做产品",而是为了把更多时间花在产品判断、用户问题和迭代上,而不是语法和样板代码上。